
Un enfoque tradicional y básico en los problemas de aprendizaje automático es utilizar un único y determinado algoritmo o modelo en la implementación de una solución válida. Este método tradicional se basa en crear un pipeline de todos los procesos que engloban el desarrollo de este algoritmo.
Esta tubería de procesos o pipeline consta de varias fases: procesamiento ETL, análisis de datos, implementación y entrenamiento del modelo, análisis de los resultados basándose en métricas determinadas y otros mecanismos de depuración, y por último, la puesta en producción del modelo.
Principalmente, en la fase de investigación e implementación del modelo, se utiliza uno o varios algoritmos determinados como posible solución al problema dada su categoría. Como es evidente, en un problema de predicción de una variable cuantitativa, se escogerán algoritmos de regresión. En un enfoque más elaborado, donde el número de características o features es tan grande que el análisis supervisado e interpretación de los resultados toma un alto grado de complejidad, es posible separar el problema en varias fases utilizando meta algoritmos.
En esta situación, el ciclo de prueba, ajuste y error es fundamental en la búsqueda del algoritmo o modelo con los hiperparámetros correctos.
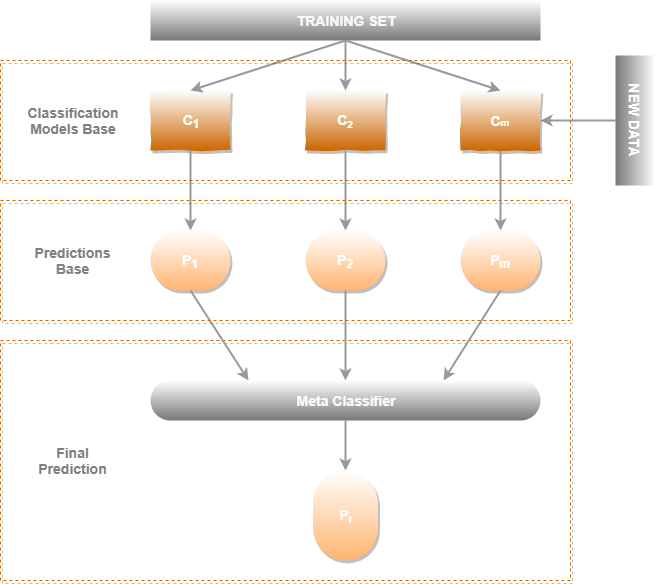
Una solución paralela es la composición de algoritmos base y un meta algoritmo superior. Este conjunto de algoritmos forman una pila, siendo el meta algoritmo el último eslabón de la cadena, mientras que los algoritmos base serán los algoritmos que se ejecutarán en paralelo para alimentar su entrada.
En este enfoque de arquitectura, los algoritmos base toman como entrada diferentes conjuntos de características, pudiendo llegar a compartir alguna de ellas. De esta manera, tendremos diferentes modelos para cada conjunto de features determinado. La forma de separar estos conjuntos se basa en el análisis previo de los datos, o en su defecto la fuente de ingesta.
En la práctica, un problema no trivial como la detección de transacciones fraudulentas o fraudes financieros, la cantidad de atributos a manejar se puede volver incontrolable. Utilizando la estructura de meta algoritmos, se determina utilizar un tipo de algoritmo por cada fuente de datos o conjunto de características determinadas y poder determinar qué features son esenciales o pueden mejorar la capacitación del modelo final.
Además, se pueden estudiar diferentes modelos para diferentes conjuntos de atributos y poder analizar mejor la correlación que existe entre ellos. Maximiza la capacidad de escoger el modelo correcto y el conjunto de features predominante en la capacitación del modelo.
En esta arquitectura el meta algoritmo utiliza el porcentaje de precisión o metrica asociada a cada uno de los algoritmos base, utilizando como target u objetivo la etiqueta binaria, en este caso true o false.
En el análisis del meta algoritmo es necesario utilizar SHAP para determinar cuál de los algoritmos base es el más relevante para las predicciones y etiquetas reales.
SHAP es un enfoque para explicar el resultado de los modelos o algoritmos de machine learning. Interioriza la teoría de juegos con métodos de explicación local para representar las posibles features basadas en expectativas. Detecta la correlación existente y el valor que aporta las features en el resultado del modelo.
En el siguiente ejemplo, es posible observar qué atributos contribuyen mejor en el aprendizaje del modelo.
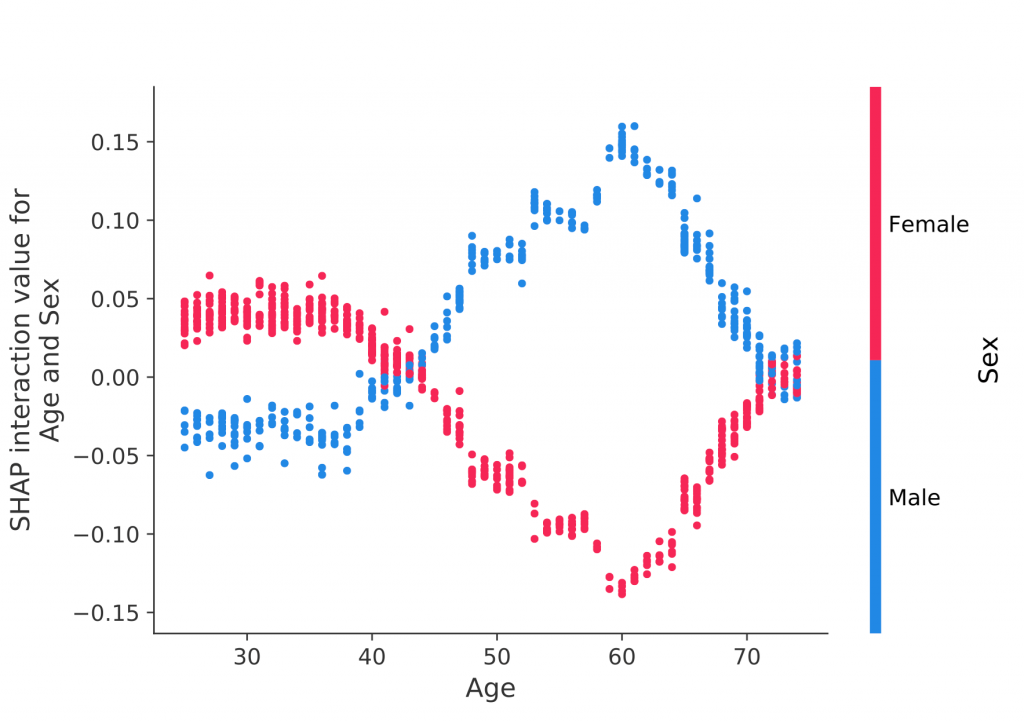
La característica del sexo y la edad, se correlacionan implícitamente en la inferencia del modelo dependiendo del rango de edad en el que se encuentre. En este ejemplo, un sexo masculino con edad aproximadamente 60 años, obtiene un impacto mayor en la capacitación del modelo. Mientras que un sexo femenino con la misma edad no destaca.
Volviendo al caso de la detección de fraude financiero, esta arquitectura además de las ventajas expuestas, presenta algunos inconvenientes.
La principal desventaja se presenta en la fase de implementación, entrenamiento y pruebas. Esto es debido a la batería de algoritmos base a implementar y entrenar. El desarrollo del código se vuelve algo complejo, el entrenamiento computacionalmente pesado y estamos condicionados por la fuente y el volumen de datos.
El tiempo necesario para el desarrollo de todo el conjunto de algoritmos es mucho más duradero que la implementación de medidas tradicionales.
No obstante, como fase de investigación, ejecutando procesos batch para el procesamiento del meta algoritmo con diferentes configuraciones de modelos y conjuntos de features debidamente programadas, es posible alcanzar soluciones a problemas más complejos.
Como ayuda en el desarrollo de esta arquitectura, la librería MLxtend de Python hereda todos los algoritmos de Scikit-Learn para implementar la batería de modelos y alimentar un meta algoritmo principal.
Debido a la complejidad de este paradigma, es necesario comenzar la fase de investigación con soluciones más sencillas. En el principio de parsimonia o más conocido como la Navaja de Ockham:
“En igualdad de condiciones, la explicación más sencilla suele ser la mejor.“
Esta formulación aplicada en el campo de la teoría de aprendizaje estadístico y computacional, se podría expresar de la siguiente manera:

