Seguro que últimamente has oído hablar de Machine Learning y es que cada vez son más los ámbitos en los que se aplica esta disciplina científica. Esto se debe a dos principales motivos: el gran avance tecnológico, en especial la capacidad de computación, y la ingente cantidad de datos de los que disponemos en la actualidad.
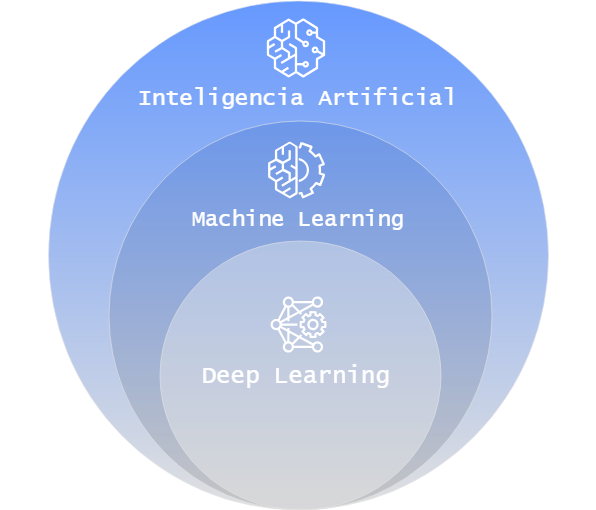
El Machine Learning, en español Aprendizaje Automático, es una rama perteneciente a la inteligencia artificial que se enfoca en el estudio de algoritmos para crear modelos de predicción.
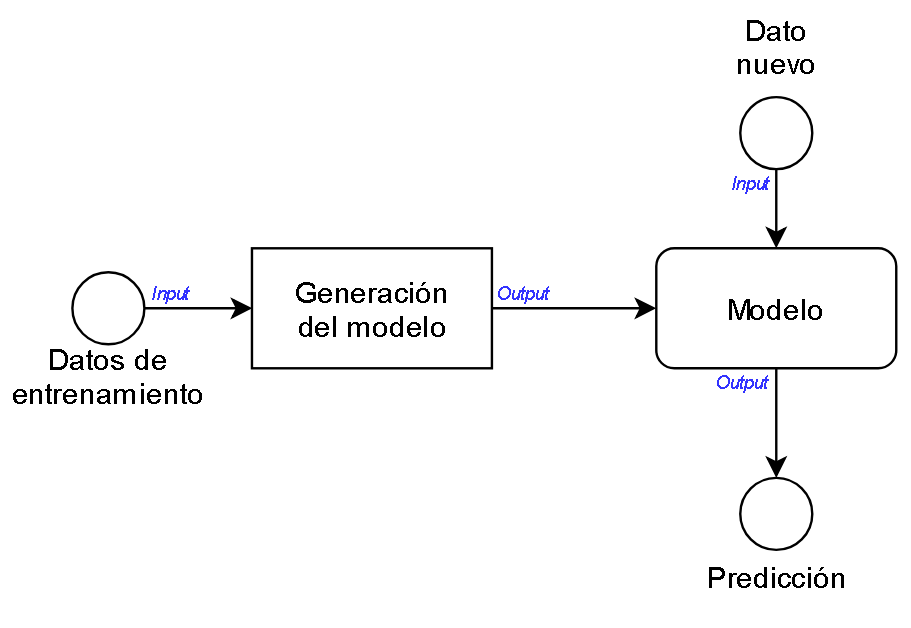
Su funcionamiento a grandes rasgos es el siguiente: a partir de unos datos de entrenamiento, se genera un modelo matemático, basado en disciplinas como la estadística y el álgebra. A este modelo posteriormente se le introducirán nuevos datos para que realice la predicción, como se muestra en la ilustración 2. En el proceso de entrenamiento del modelo, se dividen los datos de entrada en dos o tres conjuntos. Uno de ellos está destinado al propio entrenamiento siendo el conjunto más grande. El segundo se utiliza para testear el modelo y el tercero para la validación. Este último es opcional, ya que depende de la cantidad de datos de los que dispongamos. Como norma general se recomienda que la proporción de datos destinados al entrenamiento frente a los destinados al test debe ser siempre mayor. En el caso de utilizar un conjunto extra para la validación, se suele dividir el conjunto de test destinando una parte a este último conjunto. Por ejemplo, si se destina un 60% a entrenamiento y un 40% a test, este último porcentaje se divide quedando con la siguiente distribución: un 20% para test y el 20% restante para validación.
Existe una gran variedad de algoritmos, los cuales están agrupados en tres categorías principales, en función del tipo de aprendizaje que se realiza en la creación del modelo matemático. Las explicamos a continuación.
1. Aprendizaje supervisado o Supervised Learning
En el aprendizaje supervisado se crea un modelo matemático predictivo, que se genera al aplicar determinados algoritmos a un conjunto de datos, los cuales ya tienen su correspondiente categoría. Es decir, cada elemento del conjunto tiene asociada una etiqueta en la que se define a qué categoría corresponde dicho elemento, con el fin de introducir datos no clasificados al modelo y que éste nos proporcione la categoría a la que pertenecen.
El proceso de generación se basa en realizar la clasificación de los elementos del conjunto de entrenamiento y comparar el resultado con la etiqueta asociada a cada elemento. Dicho proceso se realiza de forma iterativa para ajustar el modelo predictivo.
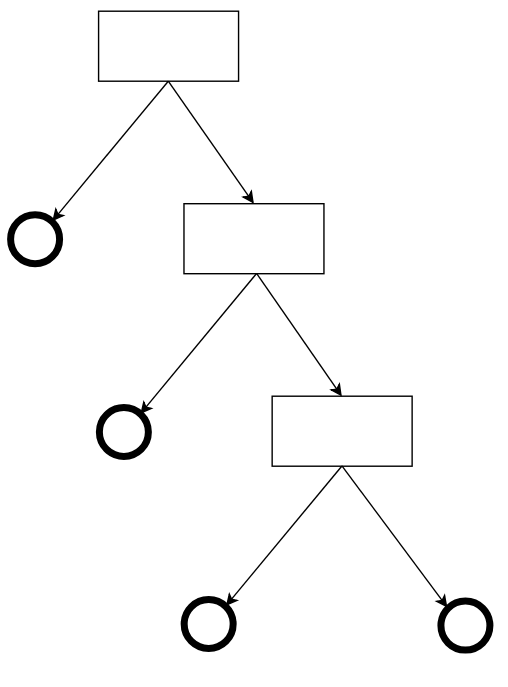
Uno de los algoritmos de aprendizaje supervisado más conocidos está basado en Árboles de decisión, que utiliza la técnica de “divide y vencerás” para realizar la clasificación de los datos de entrada, teniendo en cuenta las características/propiedades de éstos. Este algoritmo en especial se basa en la probabilidad, utilizando el valor de entropía, que refleja el nivel de incertidumbre o de desorden, mostrando cuáles de los atributos de los datos son más relevantes en el proceso de toma de decisiones. Este valor está comprendido entre 0 y 1.
2. Aprendizaje no supervisado o Unsupervised Learning
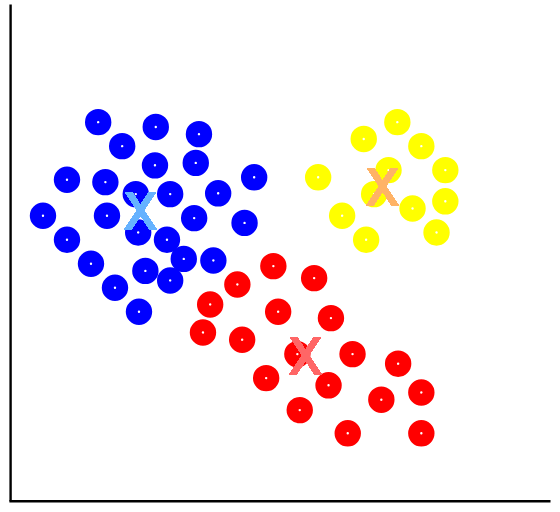
Al contrario que en la categoría anterior, en el aprendizaje no supervisado, el conjunto de datos de entrenamiento utilizado no dispone de etiquetas. Por lo tanto, estos algoritmos sólo tienen en cuenta los atributos/características de estos datos. Dentro de esta categoría los algoritmos más conocidos se basan en el proceso de agrupación, conocido como clustering.
Un ejemplo de algoritmo perteneciente a este tipo de aprendizaje es el llamado K-Means, o K-medias, cuya finalidad es realizar la agrupación en k grupos de datos en función de sus características/atributos. Se basa en el uso de la distancia cuadrática.
El algoritmo se divide en cuatro fases:
-Se establecen k centros en el espacio vectorial en que se está trabajando y éstos pueden ser seleccionados de diferentes maneras, una de ellas es al azar.
-Una vez están definidos los centros, se asocian los datos al centro con la media más cercana.
-A continuación, el algoritmo vuelve a calcular la posición de los centros respecto a los datos que tienen asociados a cada uno.
-Se repiten las fases 2 y 3 iterativamente, tantas veces como se configure. Lo ideal es configurar el número de repeticiones hasta que se llegue a la convergencia.

3. Aprendizaje por refuerzo o Reinforcement Learning
Comprende los algoritmos que más se asemejan al aprendizaje humano, ya que se basa en prueba y error. Para lograr este comportamiento, se implementa una función de recompensa/castigo. Los datos de entrenamiento se etiquetan mediante una función matemática que puede ser discreta o lineal. En este tipo de aprendizaje es más importante el proceso de toma de decisiones para llegar al objetivo que la propia solución.
Es decir, tras cada decisión que toma el algoritmo hasta llegar al objetivo se le da una recompensa, cuyo valor depende de lo acertada que sea la decisión tomada.
Tras llegar a la solución, se evalúa la calidad de las decisiones tomadas en base al conjunto de recompensas/castigos que ha ido obteniendo durante el proceso de resolución del problema.
Los problemas en los que se aplican este tipo de algoritmos tienen dos componentes principales:
-Un agente, que representa la entidad que realiza las acciones/decisiones, en este caso el algoritmo.
-Y un entorno, que representa el contexto del problema.
En resumen, este tipo de aprendizaje tiene como fin optimizar el proceso de hallar la solución a un determinado problema.
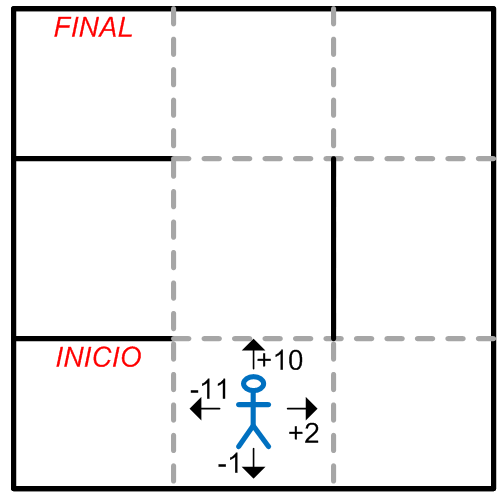
Un ejemplo de aplicación de este tipo de aprendizaje lo podemos encontrar en algoritmos de resolución de laberintos. En este caso particular, el contexto es el propio laberinto que dispone de atributos como la distribución -entre otros- y el agente es el algoritmo que se aplica para resolverlo.
En cada paso que da el agente se le recompensa o castiga con un valor que va acumulando. En el caso de que avance contra una pared, obtendrá un valor negativo como “castigo”, y en el caso de que avance hacia un camino se le entregará un valor positivo que variará en función de lo bueno que sea ese camino al que se dirige, como se representa en la ilustración 7.
El algoritmo tras llegar al final dispondrá de la acumulación de recompensas/castigos y dicho valor le otorgará la información de cuan bueno es el camino que ha recorrido. Se considerará el entrenamiento finalizado cuando haya encontrado el camino óptimo, es decir, el camino en el que el valor de recompensa acumulado sea el mayor.
Overfitting y Underfitting
Para finalizar el artículo, queremos mencionar dos situaciones problemáticas que se pueden dar durante y tras el entrenamiento del modelo.
La primera problemática que trataremos se denomina Overfitting (en español sobre entrenamiento). Se produce cuando el modelo se ajusta tanto a los datos de entrenamiento, que cuando se introduzcan nuevos datos de una determinada categoría, si no tienen exactamente las mismas características que los datos de entrenamiento pertenecientes a esa misma categoría, no serán clasificados correctamente.
Por ejemplo, en un algoritmo de clasificación de animales, si en sus datos de entrenamiento dispone únicamente de características de un determinado perro y se produce esta problemática, cuando al modelo se le introduzcan nuevos datos de un perro con características distintas al del entrenamiento, este no será reconocido como un perro.
Y el segundo caso se denomina Underfitting, que es lo opuesto al anterior. Sucede cuando el modelo se ajusta tan poco, que no es capaz de realizar una clasificación/predicción aceptable, aunque los datos nuevos dispongan de características muy similares a los datos utilizados durante el entrenamiento.
Si te interesa saber más sobre esta disciplina científica, ¡estate atento! En próximos artículos nos adentraremos un poco más en el mundo del Machine Learning.

